
Have you ever wondered how to scrape Webpages easily and efficiently?
Well, I have. I have wondered about this question for a long time. As a digital marketing researcher, I want to understand what types of digital content generate user engagement and travel far.
I have tried to get some data to answer this question. What I did was to visit blogs, copy individual posts one by one, paste them onto a Word document, and analyze them based on a pre-established coding scheme. But, that was pretty time-consuming and laborious.
I have wondered many times what if I could somehow extract Webpages out there without doing this time-consuming work. That could significantly improve data collection efficiency.
Apparently there is a technique called Web scraping. It allows you to pull data out of Webpages. I found that Python library called Beautiful Soup is a great tool for Web scraping. But, I feel a bit scared of trying serious programming language like Python. So, I decided to learn this technique with R, which people have told me is perhaps easier to get into.
There are many R tutorials online that help beginners like me understand the basics of Web scraping – I particularly enjoyed the Web scraping tutorial posted by Professor Boehmke. In this post, I use R and rvest package to try to scrape HTML text.
How to Scrape a Webpage with R
Based on what I have learned from online tutorials about Web scraping, I will scrape Donald Trump’s tax plan page – I hope he can fulfill what he promised to the public in his campaign.
To scrape HTML text with R, apparently you need a package called rvest. It looks like the basic steps are (1) you first store page content with read_html, specify what HTML element to pull out with html_nodes, and extract HTML text with html_text.
Step 1: Install and load rvest
I use RStudio. I tried R console, but it was a bit too much for me. Every time I made mistakes, I had to retype everything. So, I gave up and am now using RStudio.
I knew I had to do first was to install and load rvest package. But, when I tried to load rvest, I got the message “loading required package: xml2.” Online tutorials I read did not mention this message, so I don’t fully know why xml2 is required to use rvest. But, I guess I just had to do it.
- Also, when I tried to install rvest package, a window popped up showing that “one or more of the packages that will be updated by the installation are currnetly loaded. Restarting R prior to updating these packages is strongly recommended…” So, I just clicked Yes to restart R prior to installing.
install.packages("rvest")
library(xml2)
library(rvest)
Step 2: Read a page of interest
The simple code below apparently passes the content of the page to the variable “trump.”
trump <- read_html("https://www.donaldjtrump.com/policies/tax-plan/")
Step 3: Find a specific HTML node
But, I don’t need all content elements on this page such as navigation menu and footer. I just want to extract Trump’s tax plan in the main content area. If I want to do that, I first need to find which HTML element contains his tax plan.
To do this, I can use Google Chrome’s Inspect tool (it seems you can also use Chrome’s Selectorgadget extension by Hadley Wickham – there are many great tools and smart people out there!). So, I right-click on his tax plan page and activate Inspect tool. As I move my mouse on Elements area, page elements I scroll over get highlighted. It looks like his tax plan is contained in the element <div class=”press_item”>.
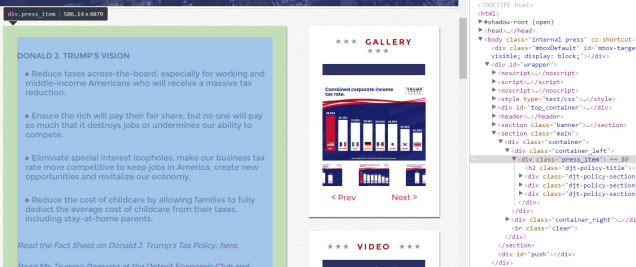
Step 4: Extract HTML text
With this selector in mind, I type the following codes.
trumptax <- trump %>%
html_nodes(css=".press_item") %>%
html_text()
The first line means that the page content stored in the variable “trump” is now assigned to a new variable “trumptax.” %>% after “trump” is called the pipe operator. If I understand it correctly (please forgive my lack of knoweldge if not – I am learning this as I am doing it), this pipe operator passes trumptax to the next line.
The second line means that I am extracting all HTML elements inside .press_item. %>% pipe operator means that I am passing the results of html_nodes (the content inside .press_item) to the next line.
- What I am struggling here is that I was not exactly sure what to type inside html_nodes (). As you can see above, I type css=”.press-item” inside the parentheses – I just learned it from online search. It seems this works when a div tag does not have a specific ID but a simple class attribute – if it does, you can use a hash (#) character instead (“#press_item”)? I hope someone can help me understand this.
Then, the final line means that I am extracting only HTML text out of all HTML elements contained inside .press_item. Then, I get this result.
[1] "\n\n\nDONALD J. TRUMP’S VISION\nReduce taxes across-the-board, especially for working and middle-income Americans who will receive a massive tax reduction.Ensure the rich will pay their fair share, but no one will pay so much that it destroys jobs or undermines our ability to compete.Eliminate special interest loopholes, make our business tax rate more competitive to keep jobs in America, create new opportunities and revitalize our economy.Reduce the cost of childcare by allowing families to fully deduct the average cost of childcare from their taxes, including stay-at-home parents. Read the Fact Sheet on Donald J. Trump’s Tax Policy, here.Read Mr. Trump's Remarks at the Detroit Economic Club and the New York Economic Club.\n\n\nTax Law Changes\nThe Trump Plan will revise and update both the individual and corporate tax codes:Individual Income TaxTax ratesThe Trump Plan will collapse the current seven tax brackets to three brackets. The rates and breakpoints are as shown below. Lo...
If I don’t use this html_text(), I just get a bunch of HTML syntax like below.
[1] <div class="press_item">\n <h2 class="djt-policy-title"/>\n <div class="djt-policy-secti ...
Next Step
I guess this is a very simple thing to do for many people, but it took me some time to understand it! Scraping Webpages is good, but it’s just one small step toward a larger goal. It seems the next step is to clean the data I pulled out. As you can see in the above HTML text, it contains some characters (e.g., “\n”) that I don’t really need for my data analysis. I need to learn how to do that now.
Hope what I presented above is all correct. Assuming that is the case, it looks like extracting data from a single page can be done with relative ease. I guess my question now is how to extract data from multiple pages with this technique. I don’t know how to do it with my very rudimentary understanding of this technique and R in general. If you know the answer, please let me know!
Happy learning and type it hard!
Image courtesy of geralt

2 thoughts on “How To Scrape Webpages with R – A Beginner’s Attempt to Scrape HTML text”